Non-linear decision boundary
The following exercise experiments with a dataset (see visualization in the cell below), where a linear model cannot seperate the different classes in the data.
Run the cell below to load libraries and functions and construct the dataset:
import numpy as np # numeriacal computing
import matplotlib.pyplot as plt # plotting core
def accuracy(predictions,targets):
"""
:param predictions: 1D-array of predicted classes for the data.
:param targets: 1D-array of actual classes for the data.
:return: fraction of correctly predicted points (num_correct/num_points).
"""
acc = np.sum(predictions == targets)/len(predictions)
return acc
### Data generation
q1 = np.random.multivariate_normal([0, 0], [[.5, 0], [0, .5]], 400)
t = np.linspace(0, 2 * np.pi, 400) ##
q2 = np.array([(3 + q1[:, 0]) * np.sin(t), (3 + q1[:, 1]) * np.cos(t)]).TThe data of the two classes (class 1
and class 2
) are stored in the variables q1
and q2
, respectively. The following cell visualize the dataset of the two classes. class 1
is labelled with 0s and class 2
with 1s.
fig, ax = plt.subplots()
ax.plot(q2[:, 0], q2[:, 1], "o", label='class 2')
ax.plot(q1[:, 0], q1[:, 1], "o", label='class 1')
plt.title("Non-linear data", fontsize=24)
ax.axis('equal')
plt.legend()
plt.show()
# write your reflections here
Accuracy of learned boundary: 0.521
def circle_boundary(t, radius):
"""
:param t: angle data points of the circle.
:param radius: radius of the circle
:return: (x-values,y-values) of the circle points .
"""
return (radius * np.cos(t), radius * np.sin(t))
fig, ax = plt.subplots()
ax.plot(q2[:, 0], q2[:, 1], "o", label='class 2')
ax.plot(q1[:, 0], q1[:, 1], "P", label='class 1')
t = np.linspace(0, 2 * np.pi, 400) ### linspace of angles.
r = 3 # radius
x_c, y_c = circle_boundary(t, r)
ax.plot(x_c, y_c, "g",linewidth=2, label=r'$r^2$ = $x^2$ + $y^2$')
plt.title("Non-linear Decision", fontsize=24)
ax.axis('equal')
plt.legend()
plt.show()
# write your reflections heredef predict_circle(radius, data):
"""
:param radius: radius of the circular decision boundary.
:param data: Array containing data points to classify.
:return: Array of predictions (-1 for inside, 1 for outside the boundary).
"""
# Write your implementation here
# Calculate accuracy here
print(f'A circular decision boundary with radius: {r:1}, has an accuracy of: {(acc_1+acc_2)/2:.3f}')A circular decision boundary with radius: 3, has an accuracy of: 0.731
# write your reflections hereNon-linear transformations to the data using polar coordinates
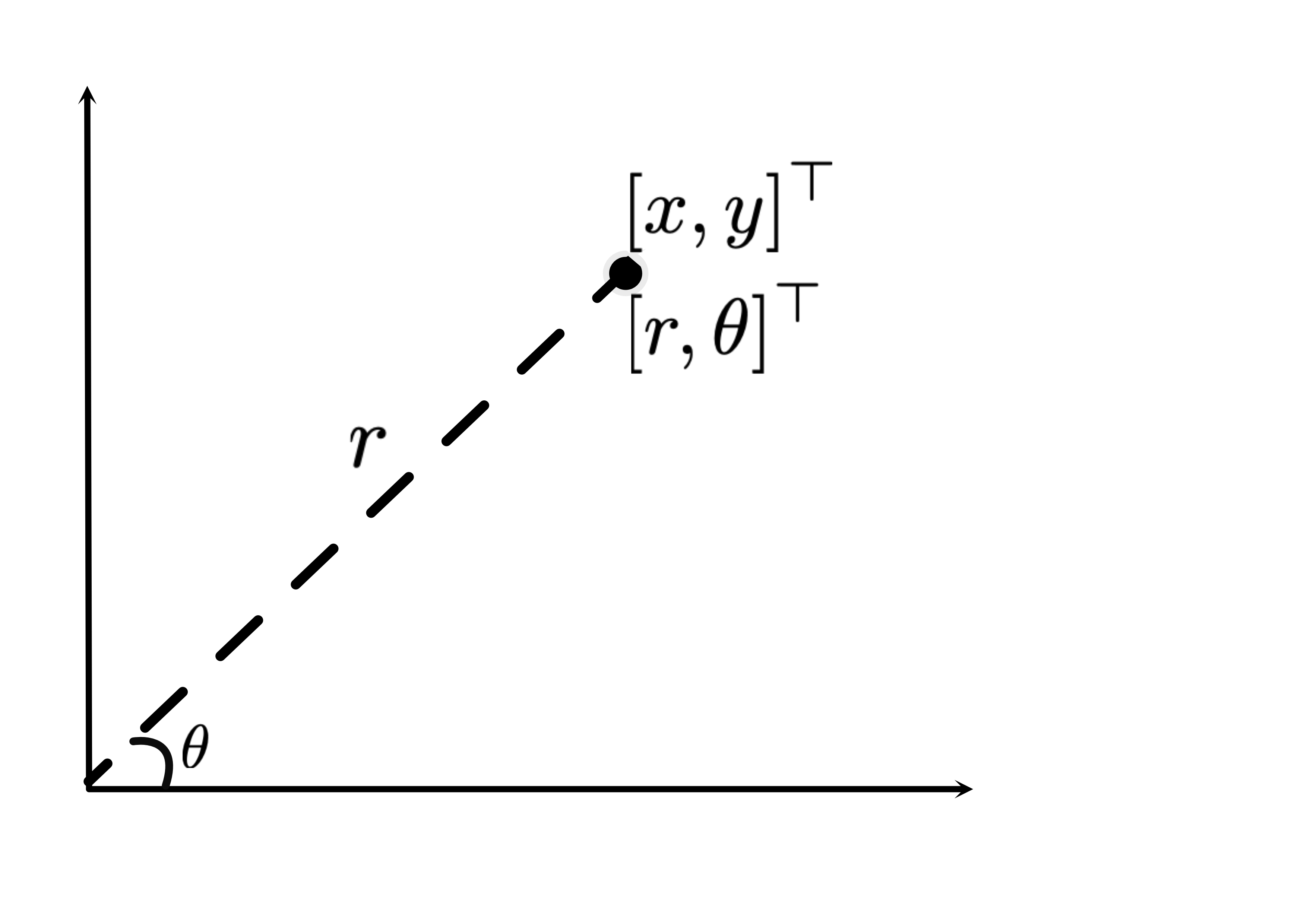
This task is about applying non-linear transformations to facilitate the use of a linear classifier. A point can be represented either by its Cartesian coordinates, $x$, $y$ , or equivalently by its polar coordinates, defined by an angle $\theta$ and distance $r$ from the origin as shown in Figure 1.
def map_to_polar_separable(data):
"""
Maps circular data centered at (0, 0) to polar coordinates (r, theta),
making the data linearly separable by radius (r).
Parameters:
- data: A numpy array of shape (N, 2) where each row is a point (x, y).
Returns:
- polar_data: A numpy array of shape (N, 2) where each row is (r, theta),
where r is the radial distance and theta is the angle in radians.
"""
# Convert to polar coordinates
r = np.sqrt(data[:, 0]**2 + data[:, 1]**2) # Radial distance
theta = np.arctan2(data[:, 1], data[:, 0]) # Angle in radians
# Stack r and theta to form polar data
polar_data = np.column_stack((r, theta))
return polar_data
data = np.vstack([q1, q2])
polar_data=map_to_polar_separable(data)
# Split polar data into classes
polar_q1 = polar_data[:len(q1)]
polar_q2 = polar_data[len(q1):]
# Plot data in polar coordinates
fig, ax = plt.subplots(figsize=(8, 8))
ax.plot(polar_q1[:, 1], polar_q1[:, 0], "o", label="Class 1", color="orange")
ax.plot(polar_q2[:, 1], polar_q2[:, 0], "o", label="Class 2", color="blue")
plt.xlabel("Radius (r)")
plt.ylabel("Angle (θ)")
plt.title("Data in Polar Coordinates")
plt.legend()
plt.show()
# Write reflections here